Basic workflow for text analysis
Obtain your text sources
Text data can come from lots of areas:
- Web sites
- Databases
- PDF documents
- Digital scans of printed materials
The easier to convert your text data into digitally stored text, the cleaner your results and fewer transcription errors.
Extract documents and move into a corpus
A text corpus is a large and structured set of texts. It typically stores the text as a raw character string with meta data and details stored with the text.
Transformation
Examples of typical transformations include:
- Tagging segments of speech for part-of-speech (nouns, verbs, adjectives, etc.) or entity recognition (person, place, company, etc.)
- Standard text processing - we want to remove extraneous information from the text and standardize it into a uniform format. This typically involves:
- Converting to lower case
- Removing punctuation
- Removing numbers
- Removing stopwords - common parts of speech that are not informative such as a, an, be, of, etc.
- Removing domain-specific stopwords
- Stemming - reduce words to their word stem
- “Fishing”, “fished”, and “fisher” -> “fish”
Extract features
Feature extraction involves converting the text string into some sort of quantifiable measures. The most common approach is the bag-of-words model, whereby each document is represented as a vector which counts the frequency of each term’s appearance in the document. You can combine all the vectors for each document together and you create a term-document matrix:
- Each row is a document
- Each column is a term
- Each cell represents the frequency of the term appearing in the document
However the bag-of-word model ignores context. You could randomly scramble the order of terms appearing in the document and still get the same term-document matrix.
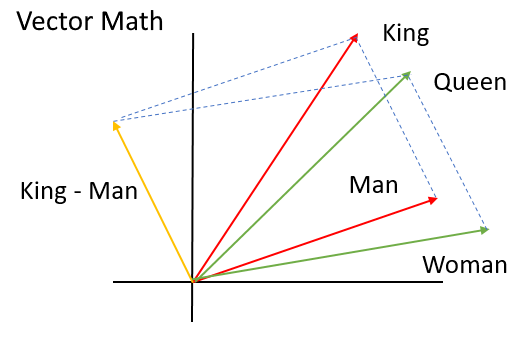
An alternative encoding method is word embeddings. Word embeddings take a high-dimensional dataset (for instance, documents with thousands or tens of thousands of unique words) and compress it into a lower-dimensional dataset that maintains the same basic configuration and sets of relationships between words. Each word is encoded as a vector, or a set of coordinates in geometric space. If the word embedding space represents the semantic meaning of words, we can see these semantic relationships with some basic algebraic operations.
Perform analysis
At this point you now have data assembled and ready for analysis. There are several approaches you may take when analyzing text depending on your research question. Basic approaches include:
- Word frequency - counting the frequency of words in the text
- Collocation - words commonly appearing near each other
- Dictionary tagging - locating a specific set of words in the texts
More advanced methods include document classification, or assigning documents to different categories. This can be supervised (the potential categories are defined in advance of the modeling) or unsupervised (the potential categories are unknown prior to analysis). You might also conduct corpora comparison, or comparing the content of different groups of text. This is the approach used in plagiarism detecting software such as Turn It In. Finally, you may attempt to detect clusters of document features, known as topic modeling.
Acknowledgments
- This page is derived in part from “Tidy Text Mining with R” and licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 United States License.
- This page is derived in part from Common Text Mining Workflow.
Session Info
sessioninfo::session_info()
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.2.1 (2022-06-23)
## os macOS Monterey 12.3
## system aarch64, darwin20
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/New_York
## date 2022-08-22
## pandoc 2.18 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date (UTC) lib source
## blogdown 1.10 2022-05-10 [2] CRAN (R 4.2.0)
## bookdown 0.27 2022-06-14 [2] CRAN (R 4.2.0)
## bslib 0.4.0 2022-07-16 [2] CRAN (R 4.2.0)
## cachem 1.0.6 2021-08-19 [2] CRAN (R 4.2.0)
## cli 3.3.0 2022-04-25 [2] CRAN (R 4.2.0)
## digest 0.6.29 2021-12-01 [2] CRAN (R 4.2.0)
## evaluate 0.16 2022-08-09 [1] CRAN (R 4.2.1)
## fastmap 1.1.0 2021-01-25 [2] CRAN (R 4.2.0)
## here 1.0.1 2020-12-13 [2] CRAN (R 4.2.0)
## htmltools 0.5.3 2022-07-18 [2] CRAN (R 4.2.0)
## jquerylib 0.1.4 2021-04-26 [2] CRAN (R 4.2.0)
## jsonlite 1.8.0 2022-02-22 [2] CRAN (R 4.2.0)
## knitr 1.39 2022-04-26 [2] CRAN (R 4.2.0)
## magrittr 2.0.3 2022-03-30 [2] CRAN (R 4.2.0)
## R6 2.5.1 2021-08-19 [2] CRAN (R 4.2.0)
## rlang 1.0.4 2022-07-12 [2] CRAN (R 4.2.0)
## rmarkdown 2.14 2022-04-25 [2] CRAN (R 4.2.0)
## rprojroot 2.0.3 2022-04-02 [2] CRAN (R 4.2.0)
## rstudioapi 0.13 2020-11-12 [2] CRAN (R 4.2.0)
## sass 0.4.2 2022-07-16 [2] CRAN (R 4.2.0)
## sessioninfo 1.2.2 2021-12-06 [2] CRAN (R 4.2.0)
## stringi 1.7.8 2022-07-11 [2] CRAN (R 4.2.0)
## stringr 1.4.0 2019-02-10 [2] CRAN (R 4.2.0)
## xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0)
## yaml 2.3.5 2022-02-21 [2] CRAN (R 4.2.0)
##
## [1] /Users/soltoffbc/Library/R/arm64/4.2/library
## [2] /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library
##
## ──────────────────────────────────────────────────────────────────────────────