The basics of statistical learning
Statistical models attempt to summarize relationships between variables by reducing the dimensionality of the data. For example, here we have some simulated data on sales of Shamwow in 200 different markets.
Our goal is to improve sales of the Shamwow. Since we cannot directly increase sales of the product (unless we go out and buy it ourselves), our only option is to increase advertising across three potential mediums: internet, newspaper, and TV.
In this example, the advertising budgets are our input variables, also called independent variables, features, or predictors. The sales of Shamwows is the output, also called the dependent variable or response.
By plotting the variables against one another using a scatterplot, we can see there is some sort of relationship between each medium’s advertising spending and Shamwow sales:
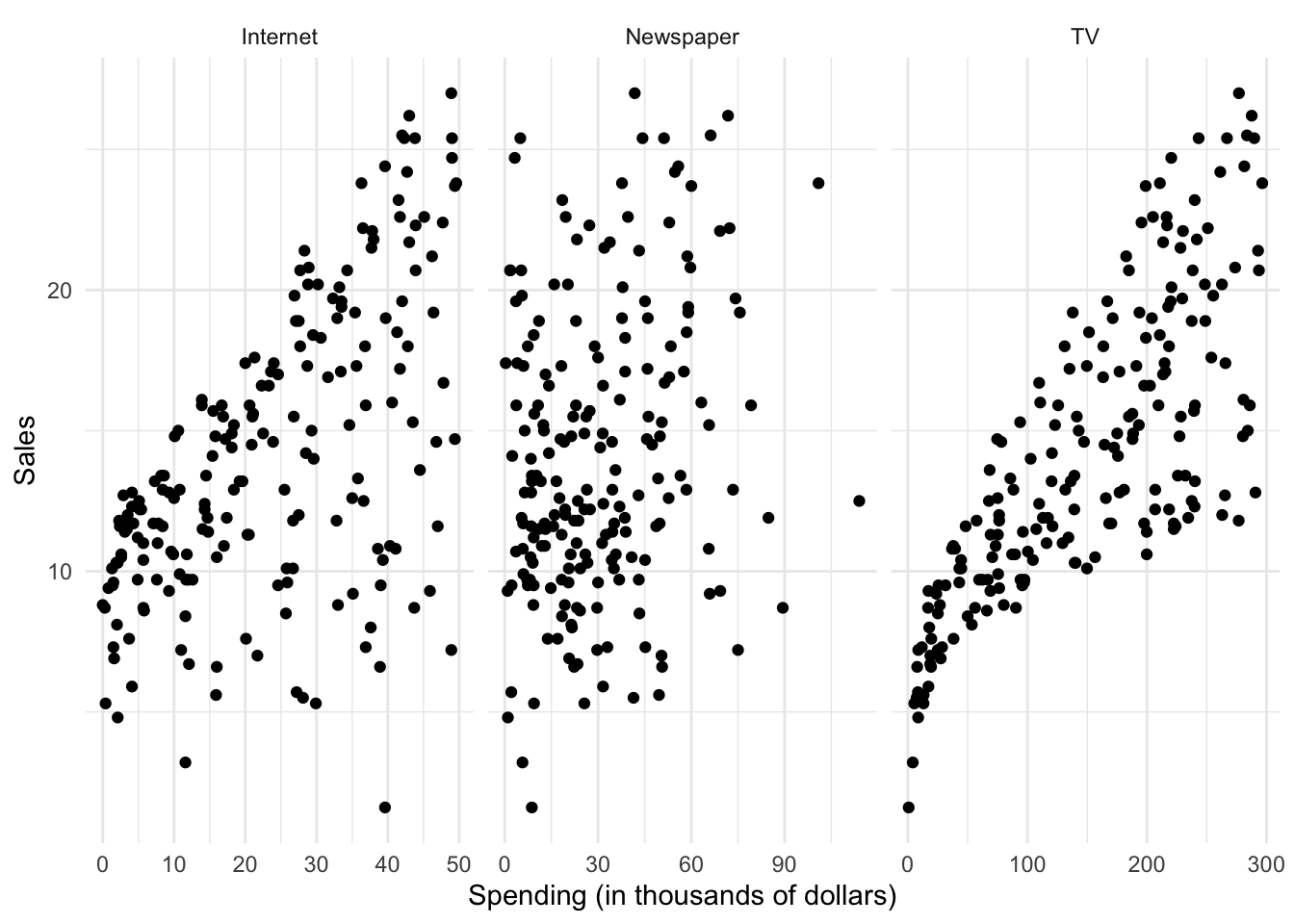
But there seems to be a lot of noise in the data. How can we summarize this? We can do so by estimating a mathematical equation following the general form:
$$Y = f(X) + \epsilon$$
where $f$ is some fixed, unknown function of the relationship between the independent variable(s) $X$ and the dependent variable $Y$, with some random error $\epsilon$.
Statistical learning refers to the set of approaches for estimating $f$. There are many potential approaches to defining the functional form of $f$. One approach widely used is called least squares - it means that the overall solution minimizes the sum of the squares of the errors made in the results of the equation. The errors are simply the vertical difference between the actual values for $y$ and the predicted values for $y$. Applied here, the results would look like:
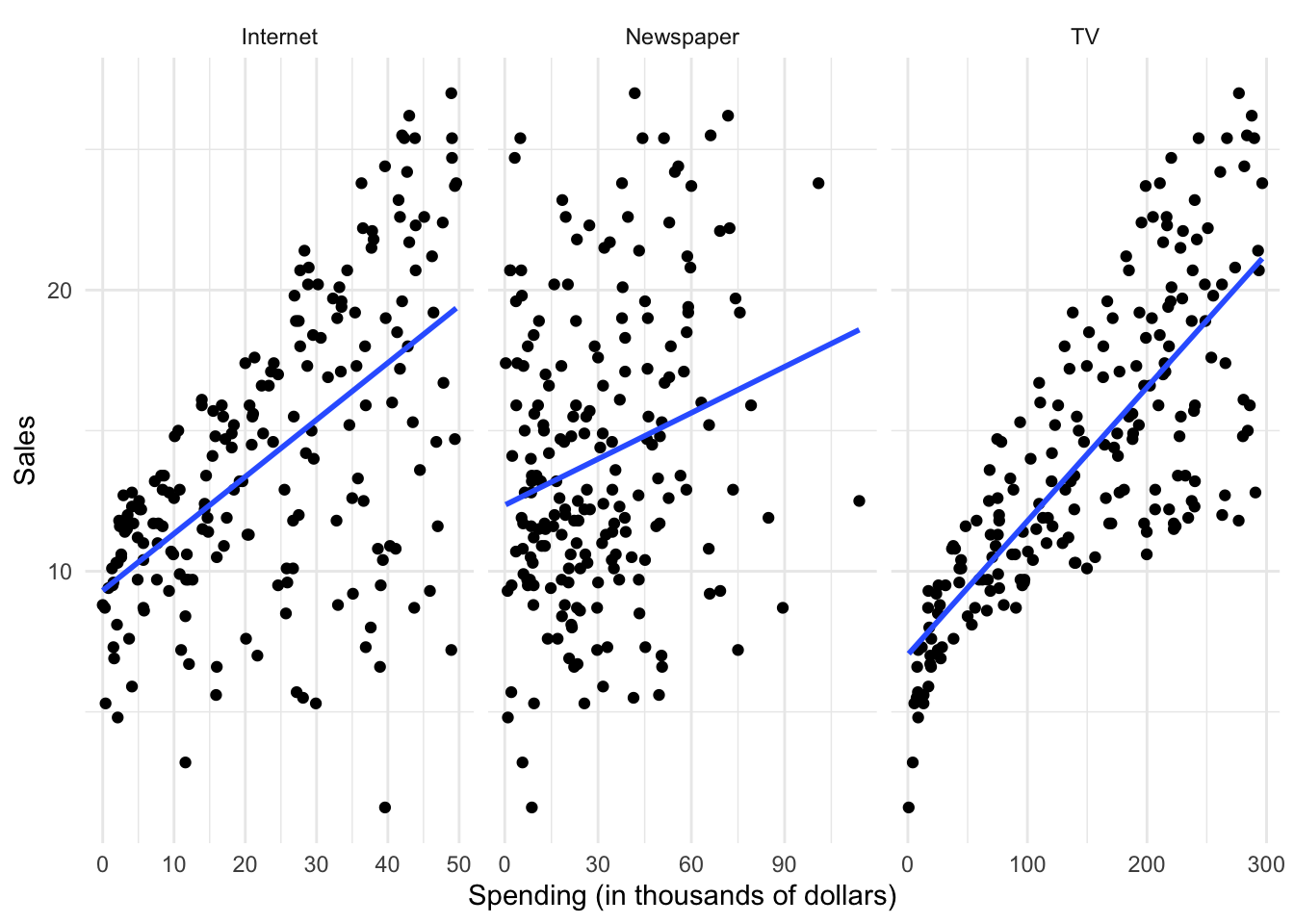
However statistical learning (and machine learning) allows us to use a wide range of functional forms beyond a simple linear model.
Why estimate $f$?
There are two major goals of statistical modeling:
Prediction
Under a system of prediction, we use our knowledge of the relationship between $X$ and $Y$ to predict $Y$ for given values of $X$. Often the function $f$ is treated as a black box - we don’t care what the function is, as long as it makes accurate predictions. If we are trying to boost sales of Shamwow, we may not care why specific factors drive an increase in sales - we just want to know how to adjust our advertising budgets to maximize sales.
Inference
Under a system of inference, we use our knowledge of $X$ and $Y$ to understand the relationship between the variables. Here we are most interested in the explanation, not the prediction. So in the Shamwow example, we may not care about actual sales of the product - instead, we may be economists who wish to understand how advertising spending influences product sales. We don’t care about the actual product, we simply want to learn more about the process and generalize it to a wider range of settings.
How do we estimate $f$?
There are two major approaches to estimating $f$: parametric and non-parametric methods.
Parametric methods
Parametric methods involve a two-stage process:
- First make an assumption about the functional form of $f$. For instance, OLS assumes that the relationship between $X$ and $Y$ is linear. This greatly simplifies the problem of estimating the model because we know a great deal about the properties of linear models.
- After a model has been selected, we need to fit or train the model using the actual data. We demonstrated this previously with ordinary least squares. The estimation procedure minimizes the sum of the squares of the differences between the observed responses $Y$ and those predicted by a linear function $\hat{Y}$.
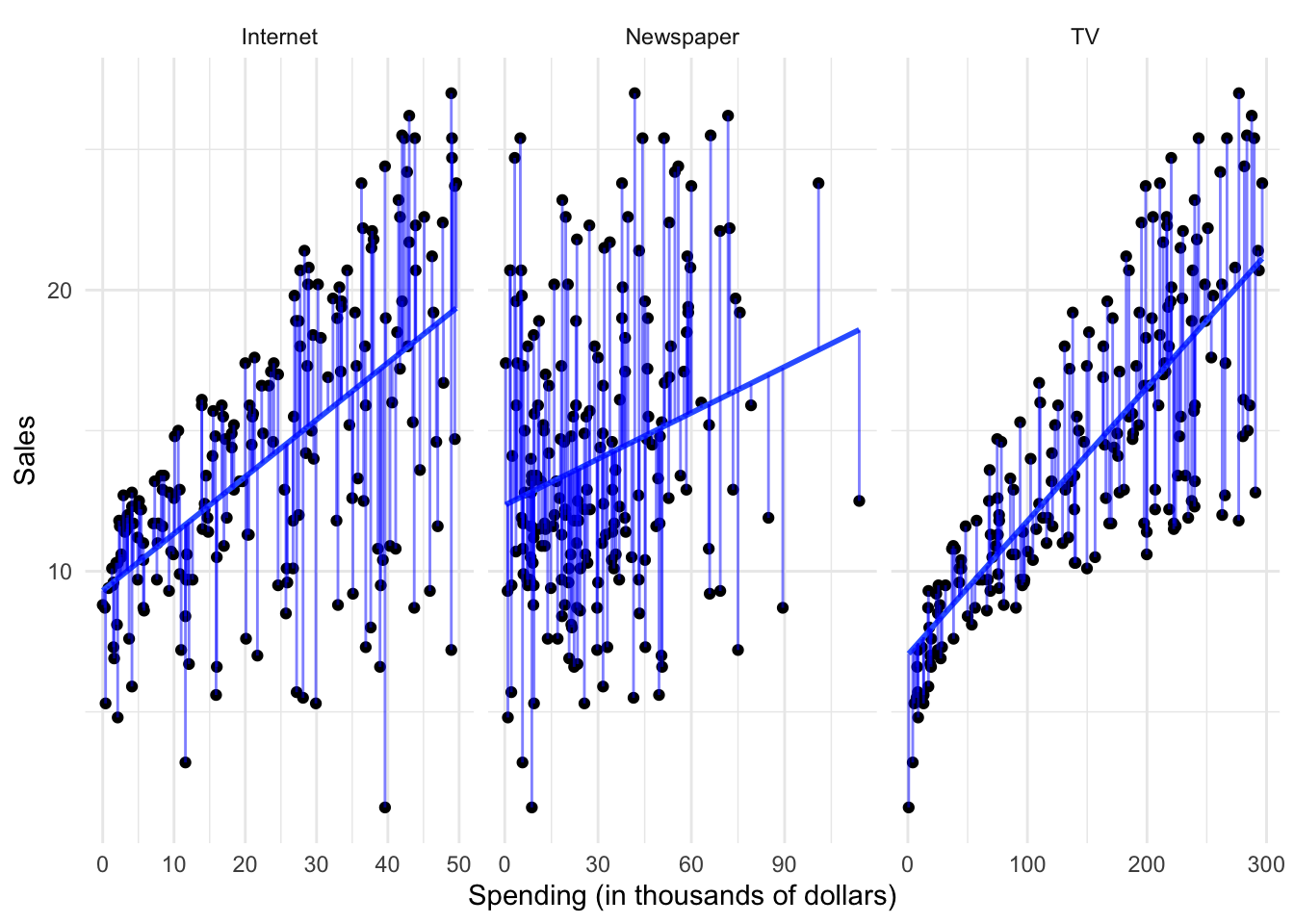
This is only one possible estimation procedure, but is popular because it is relatively intuitive. This model-based approach is referred to as parametric, because it simplifies the problem of estimating $f$ to estimating a set of parameters in the function:
$$Y = \beta_{0} + \beta_{1}X_1$$
where $Y$ is the sales, $X_1$ is the advertising spending in a given medium (internet, newspaper, or TV), and $\beta_0$ and $\beta_1$ are parameters defining the intercept and slope of the line.
The downside to parametric methods is that they assume a specific functional form of the relationship between the variables. Sometimes relationships really are linear - often however they are not. They could be curvilinear, parabolic, interactive, etc. Unless we know this a priori or test for all of these potential functional forms, it is possible our parametric method will not accurately summarize the relationship between $X$ and $Y$.
Non-parametric methods
Non-parametric methods do not make any assumptions about the functional form of $f$. Instead, they use the data itself to estimate $f$ so that it gets as close as possible to the data points without becoming overly complex. By avoiding any assumptions about the functional form, non-parametric methods avoid the issues caused by parametric models. However, by doing so non-parametric methods require a large set of observations to avoid overfitting the data and obtain an accurate estimate of $f$.
One non-parametric method is called $K$-nearest neighbors regression (KNN regression). Rather than binning the data into discrete and fixed intervals, KNN regression uses a moving average to generate the regression line. Given a value for $K$ and a prediction point $x_0$, KNN regression identifies the $K$ observations closest to the prediction point $X_0$, and estimates a local regression line that is the average of these observations values for the outcome $Y$.
With $K=1$, the resulting KNN regression line will fit the training observations extraordinarily well.
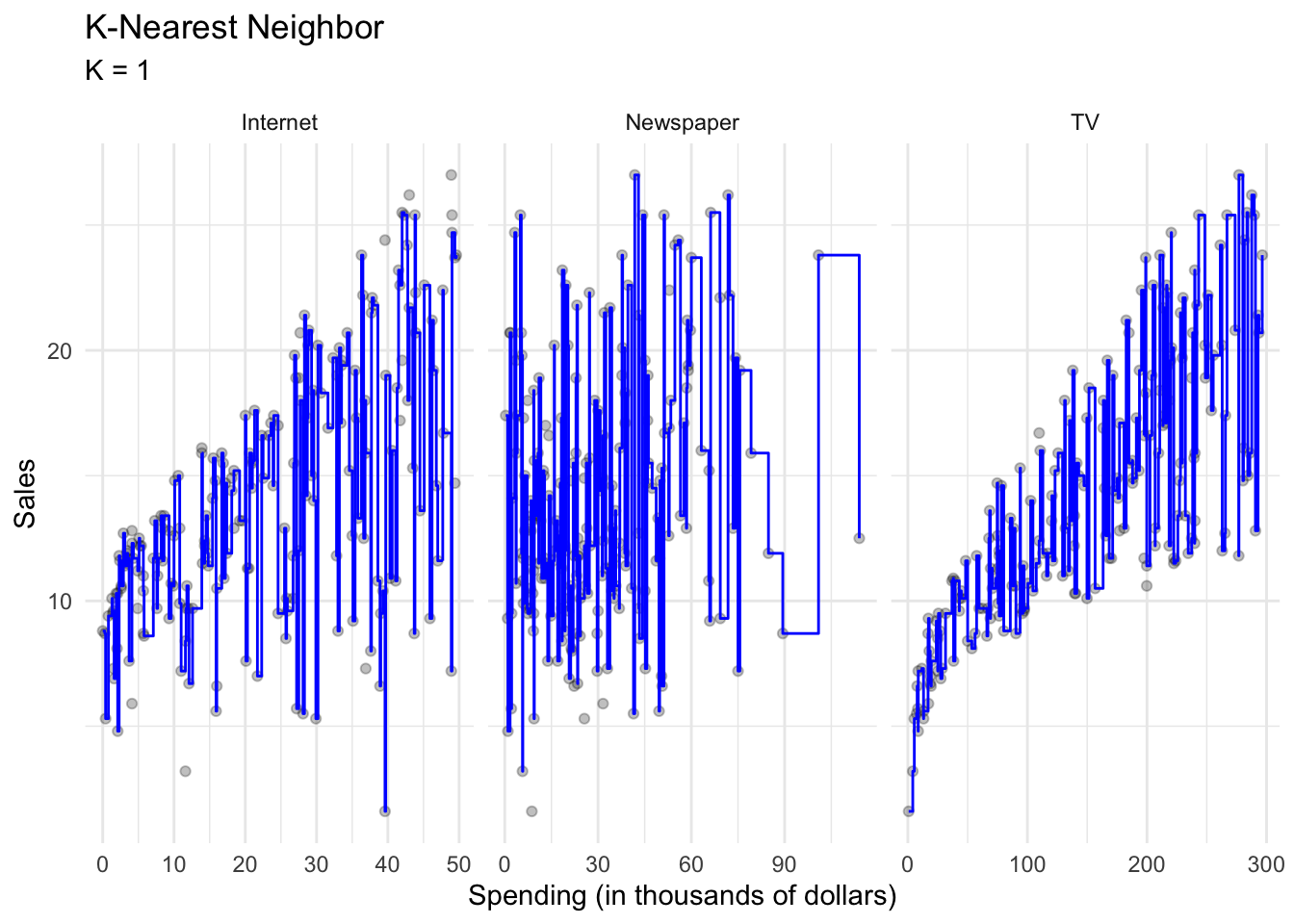
Perhaps a bit too well. Compare this to $K=9$:
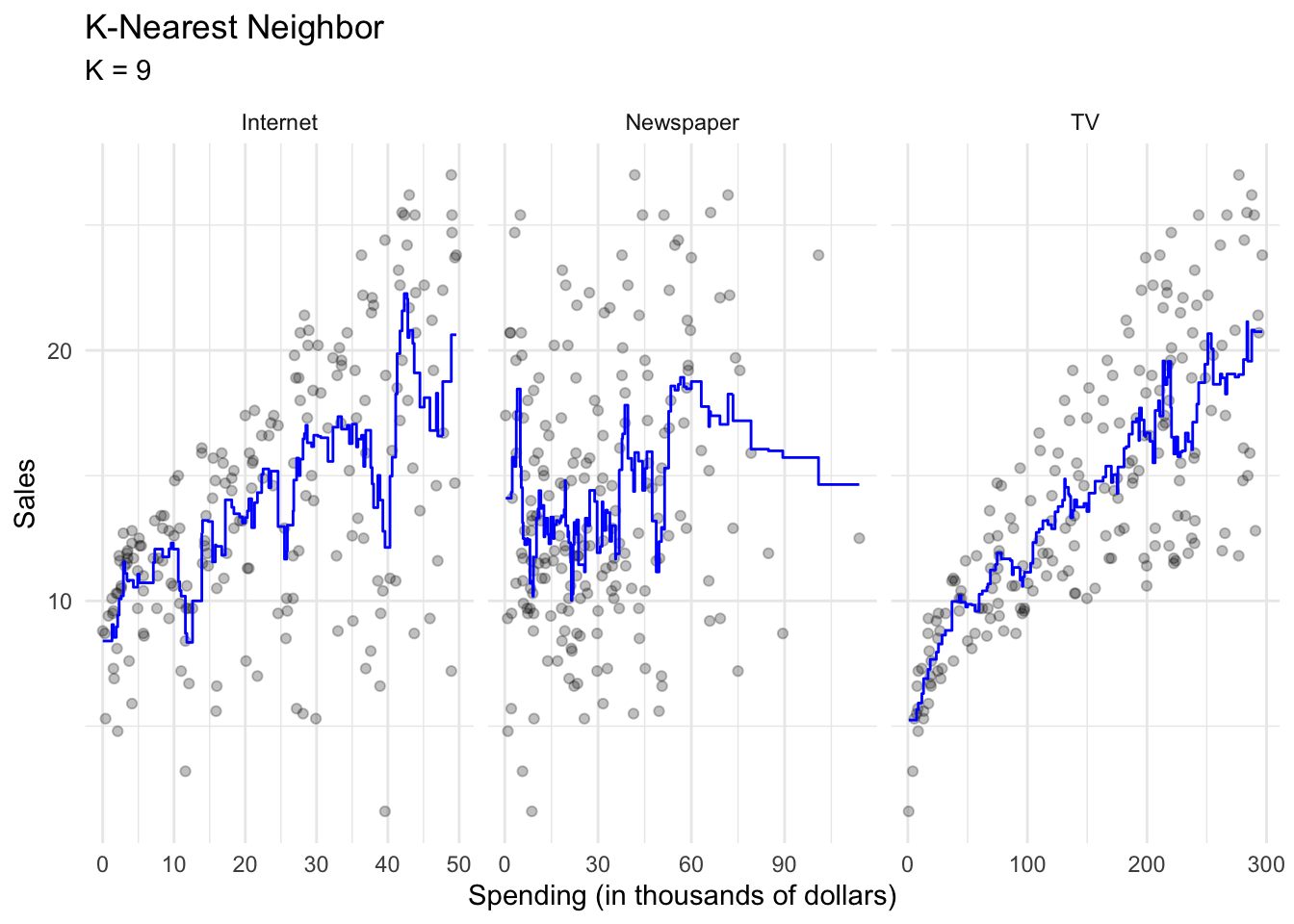
This smoothing line averages over the nine nearest observations; while still a step function, it is smoother than $K=1$.
Classification vs. regression
Variables can be classified as quantitative or qualitative. Quantitative variables take on numeric values. In contrast, qualitative variables take on different classes, or discrete categories. Qualitative variables can have any number of classes, though binary categories are frequent:
- Yes/no
- Male/female
Problems with a quantitative dependent variable are typically called regression problems, whereas qualitative dependent variables are called classification problems. Part of this distinction is merely semantic, but different methods may be employed depending on the type of response variable. For instance, you would not use linear regression on a qualitative response variable. Conceptually, how would you define a linear function for a response variable that takes on the values “male” or “female”? It doesn’t make any conceptual sense. Instead, you can employ classification methods such as logistic regression to estimate the probability that based on a set of predictors a specific observation is part of a response class.
That said, whether predictors are qualitative or quantitative is not important in determining whether the problem is one of regression or classification. As long as qualitative predictors are properly coded before the analysis is conducted, they can be used for either type of problem.
Session Info
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.2.1 (2022-06-23)
## os macOS Monterey 12.3
## system aarch64, darwin20
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz America/New_York
## date 2022-08-22
## pandoc 2.18 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date (UTC) lib source
## assertthat 0.2.1 2019-03-21 [2] CRAN (R 4.2.0)
## backports 1.4.1 2021-12-13 [2] CRAN (R 4.2.0)
## blogdown 1.10 2022-05-10 [2] CRAN (R 4.2.0)
## bookdown 0.27 2022-06-14 [2] CRAN (R 4.2.0)
## broom 1.0.0 2022-07-01 [2] CRAN (R 4.2.0)
## bslib 0.4.0 2022-07-16 [2] CRAN (R 4.2.0)
## cachem 1.0.6 2021-08-19 [2] CRAN (R 4.2.0)
## cellranger 1.1.0 2016-07-27 [2] CRAN (R 4.2.0)
## cli 3.3.0 2022-04-25 [2] CRAN (R 4.2.0)
## colorspace 2.0-3 2022-02-21 [2] CRAN (R 4.2.0)
## crayon 1.5.1 2022-03-26 [2] CRAN (R 4.2.0)
## DBI 1.1.3 2022-06-18 [2] CRAN (R 4.2.0)
## dbplyr 2.2.1 2022-06-27 [2] CRAN (R 4.2.0)
## digest 0.6.29 2021-12-01 [2] CRAN (R 4.2.0)
## dplyr * 1.0.9 2022-04-28 [2] CRAN (R 4.2.0)
## ellipsis 0.3.2 2021-04-29 [2] CRAN (R 4.2.0)
## evaluate 0.16 2022-08-09 [1] CRAN (R 4.2.1)
## fansi 1.0.3 2022-03-24 [2] CRAN (R 4.2.0)
## fastmap 1.1.0 2021-01-25 [2] CRAN (R 4.2.0)
## FNN * 1.1.3.1 2022-05-23 [2] CRAN (R 4.2.0)
## forcats * 0.5.1 2021-01-27 [2] CRAN (R 4.2.0)
## fs 1.5.2 2021-12-08 [2] CRAN (R 4.2.0)
## gargle 1.2.0 2021-07-02 [2] CRAN (R 4.2.0)
## generics 0.1.3 2022-07-05 [2] CRAN (R 4.2.0)
## ggplot2 * 3.3.6 2022-05-03 [2] CRAN (R 4.2.0)
## glue 1.6.2 2022-02-24 [2] CRAN (R 4.2.0)
## googledrive 2.0.0 2021-07-08 [2] CRAN (R 4.2.0)
## googlesheets4 1.0.0 2021-07-21 [2] CRAN (R 4.2.0)
## gtable 0.3.0 2019-03-25 [2] CRAN (R 4.2.0)
## haven 2.5.0 2022-04-15 [2] CRAN (R 4.2.0)
## here * 1.0.1 2020-12-13 [2] CRAN (R 4.2.0)
## hms 1.1.1 2021-09-26 [2] CRAN (R 4.2.0)
## htmltools 0.5.3 2022-07-18 [2] CRAN (R 4.2.0)
## httr 1.4.3 2022-05-04 [2] CRAN (R 4.2.0)
## jquerylib 0.1.4 2021-04-26 [2] CRAN (R 4.2.0)
## jsonlite 1.8.0 2022-02-22 [2] CRAN (R 4.2.0)
## knitr 1.39 2022-04-26 [2] CRAN (R 4.2.0)
## lifecycle 1.0.1 2021-09-24 [2] CRAN (R 4.2.0)
## lubridate 1.8.0 2021-10-07 [2] CRAN (R 4.2.0)
## magrittr 2.0.3 2022-03-30 [2] CRAN (R 4.2.0)
## modelr 0.1.8 2020-05-19 [2] CRAN (R 4.2.0)
## munsell 0.5.0 2018-06-12 [2] CRAN (R 4.2.0)
## pillar 1.8.0 2022-07-18 [2] CRAN (R 4.2.0)
## pkgconfig 2.0.3 2019-09-22 [2] CRAN (R 4.2.0)
## purrr * 0.3.4 2020-04-17 [2] CRAN (R 4.2.0)
## R6 2.5.1 2021-08-19 [2] CRAN (R 4.2.0)
## readr * 2.1.2 2022-01-30 [2] CRAN (R 4.2.0)
## readxl 1.4.0 2022-03-28 [2] CRAN (R 4.2.0)
## reprex 2.0.1.9000 2022-08-10 [1] Github (tidyverse/reprex@6d3ad07)
## rlang 1.0.4 2022-07-12 [2] CRAN (R 4.2.0)
## rmarkdown 2.14 2022-04-25 [2] CRAN (R 4.2.0)
## rprojroot 2.0.3 2022-04-02 [2] CRAN (R 4.2.0)
## rstudioapi 0.13 2020-11-12 [2] CRAN (R 4.2.0)
## rvest 1.0.2 2021-10-16 [2] CRAN (R 4.2.0)
## sass 0.4.2 2022-07-16 [2] CRAN (R 4.2.0)
## scales 1.2.0 2022-04-13 [2] CRAN (R 4.2.0)
## sessioninfo 1.2.2 2021-12-06 [2] CRAN (R 4.2.0)
## stringi 1.7.8 2022-07-11 [2] CRAN (R 4.2.0)
## stringr * 1.4.0 2019-02-10 [2] CRAN (R 4.2.0)
## tibble * 3.1.8 2022-07-22 [2] CRAN (R 4.2.0)
## tidyr * 1.2.0 2022-02-01 [2] CRAN (R 4.2.0)
## tidyselect 1.1.2 2022-02-21 [2] CRAN (R 4.2.0)
## tidyverse * 1.3.2 2022-07-18 [2] CRAN (R 4.2.0)
## tzdb 0.3.0 2022-03-28 [2] CRAN (R 4.2.0)
## utf8 1.2.2 2021-07-24 [2] CRAN (R 4.2.0)
## vctrs 0.4.1 2022-04-13 [2] CRAN (R 4.2.0)
## withr 2.5.0 2022-03-03 [2] CRAN (R 4.2.0)
## xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0)
## xml2 1.3.3 2021-11-30 [2] CRAN (R 4.2.0)
## yaml 2.3.5 2022-02-21 [2] CRAN (R 4.2.0)
##
## [1] /Users/soltoffbc/Library/R/arm64/4.2/library
## [2] /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library
##
## ──────────────────────────────────────────────────────────────────────────────